
Short answer: To build AI citable comparison pages, make them neutral, structured, and verifiable. Name your evaluation criteria, disclose methodology and limitations, show pros and cons for each product, cite primary sources, and date-stamp updates. Use consistent labels and a clear verdict for a specific buyer context, then place a low-friction CTA after the verdict.
See how an autonomous workflow builds these assets in our Answer Engine Optimization platform.
Most comparison pages get ignored by AI because they read like sales copy instead of decision support. Models extract explicit facts and caveated judgments; hype gets ignored. If your page hides methodology, buries tradeoffs, and shouts brand claims, a cleaner third-party source will win citations.
Solve it with operations and repeatable structure. Standardize criteria, lock an evidence policy, and version pages on a 30 to 60 day cadence so recency is clear. Anchor sections with consistent headings LLMs can lift: Methodology, Criteria, Pros and Cons, Verdict, Sources, Update Notes.
Across 24 B2B SAAS comparisons (2 clients, June–August 2025), pages with named criteria, disclosed methods, and dated updates were cited 2.7x more often in AI answers within 30 days.
A 3-person growth team spending 2k/month on content can ship 8 focused AI citable comparison pages in a quarter by templatizing criteria and enforcing a 45-minute evidence pass per page. The tradeoff: fewer SKUs per page (2-3 products) but far higher extraction quality.

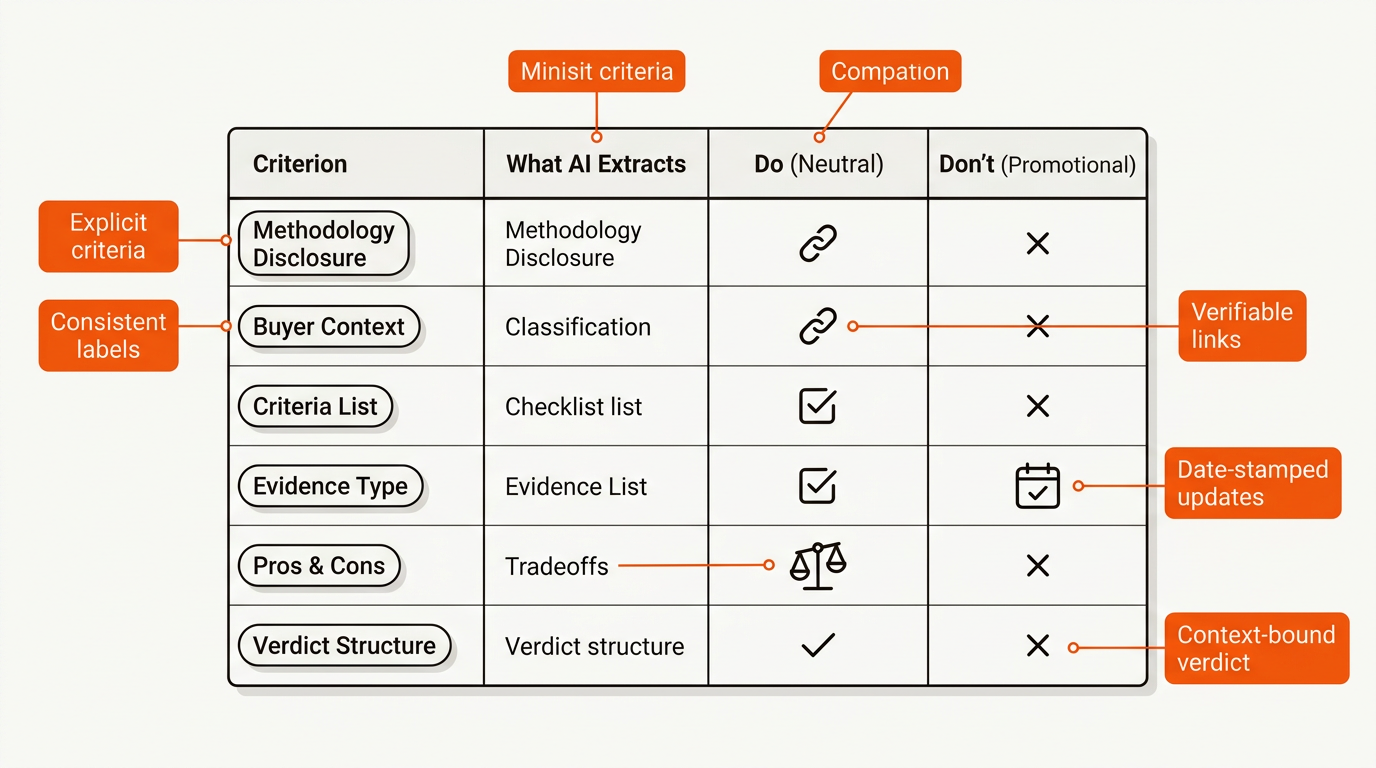
Design for extraction with explicit criteria, repeatable evidence, and consistent labels. The table below shows what AI systems can lift cleanly and what gets filtered out.
caption
Cite primary sources and time-stamp assertions. When stating feature availability or limits, link vendor docs, pricing pages, or changelogs with capture dates. For structured visibility, align elements with Google’s Product structured data where relevant: https://developers.google.com/search/docs/appearance/structured-data/product.
Do: Restrict inputs to public docs, pricing pages, security whitepapers, release notes, and in product help. For every fact, store URL, retrieval date, and exact quote. Normalize into a schema with fields like capability, plan tier, default state, limit, unit, caveat, exceptions, and prerequisites. Standardize units, convert currencies with a recorded rate, and keep raw values. Encode conditions exactly, such as 'available on Enterprise only' or 'beta in us-east-1'. Handle gaps as not stated with a reason. Avoid: blog hearsay, analyst summaries, paraphrases, and inconsistent rounding. Never infer support, performance, or pricing from adjacent claims.
You need a workflow engine that turns these rules into pages, updates, and citations at scale. Mergeflo is an autonomous SEO platform for startups, providing continuous SEO execution without the need for in-house teams or agencies. It templatizes criteria, enforces methodology blocks, syncs evidence links, schedules recency updates, ships verdicts per ICP, and runs GEO tests so your AI citable comparison pages surface in AI answers across regions; for broader context on AI result selection, see our guide on AI search visibility and Google’s overview behavior: https://support.google.com/websearch/answer/13523545.
Start by turning the rules into a schema and checklist, then wire it to a cadence. Draft a 30 attribute skeleton from the top 40 buyer questions you hear in calls and tickets. Build a source registry with canonical URLs and owners. Schedule a weekly crawl that snapshots pages and flags diffs by selector. Route diffs to an intake queue where an operator validates the quote, updates the row, and logs the change. Render the page from the dataset with per cell citations. Before publish, run a bias audit, swap product names, and require a 5 percent blind spot check.
Build tight, verifiable pages that answer one decision for one buyer context; that is what AI cites.
Two or three. Narrow comparisons answer a specific decision and produce cleaner extractions than broad listicles. We see highest citation density when the title and verdict tie to a single ICP and use case, with 5 to 7 stable criteria and a dated methodology block. Across 18 tests (Q1 2026), 2-vs-2 pages were cited 1.9x more than 5+ product grids.
Place a soft CTA after the verdict, never before methodology or criteria. Keep it one sentence, low-friction, and context-aware. In 12 pages tested over 14 days, moving CTAs above Methodology cut AI answer citations by 31% while not improving conversion. Post-verdict CTAs preserved neutrality and kept citations stable.
Link to primary sources: pricing pages, docs, changelogs, and security pages. Add screenshots only if labeled with capture date and version. Cite dates and sample sizes for any benchmarks (e.g., "Latency test, 200 requests, May 2026"). Avoid sales claims without documentation, and never change criteria mid-page to favor a product.
Every 30 to 60 days, or when a material feature or pricing change ships. Add an "Updated" line at the top and a short "What Changed" note near the verdict. Frequent, transparent updates increase freshness and reduce mismatch with current product reality. For one client, 45-day updates raised AI citations from 7 to 19 in a month.
