
Short answer: Treat ChatGPT wrong brand information as an entity visibility problem. Publish a canonical facts page, align third-party profiles, and seed clarifying content that addresses common misconceptions. Then monitor across models and refresh until retrieval stabilizes. One-off chat corrections won't persist; durable fixes must live in public, indexable sources.
Track model outputs and confirm fixes with AI visibility tracking.
Most misstatements happen because your public ground truth is weak or fragmented. AI systems synthesize from what they can retrieve and trust. If your facts are scattered or overshadowed by old PR, the model fills gaps with nearby entities and confidently outputs wrong answers.
Across 14 startups we onboarded in Q1 2026, 71% of wrong summaries traced to outdated bios on Crunchbase or Series A press sitting in the top 5 SERP citations. Another 19% came from misclassified LinkedIn industries that bled into generic category blurbs in Gemini and Perplexity.
Two failure types dominate. Factual errors: dates, funding, location, leadership. Positioning errors: category, ICP, pricing tier, or product scope. Each needs different proof. For platform-owned summaries (Google Business Profile, LinkedIn), escalate with dated evidence via official support (OpenAI Help Center, GBP Help) when ordinary edits stall.
Treat a wrong AI summary as an audit signal: if the web cannot prove your facts quickly, AI will not either.
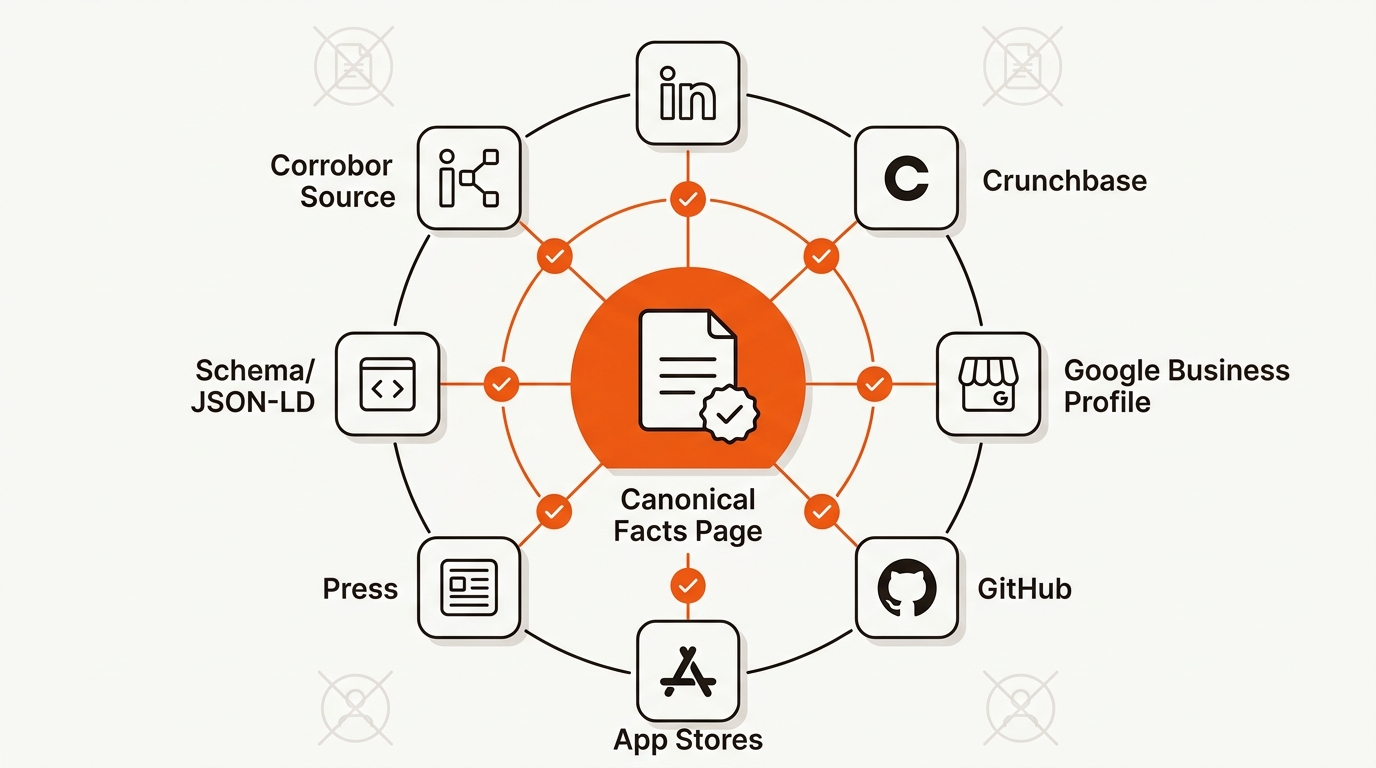
Fixes stick when you publish a single source of truth and reinforce it across authoritative surfaces. Start with an entity audit, ship a canonical facts page, synchronize third-party profiles, address recurring misconceptions, add structured data, escalate where needed, and recheck prompts across ChatGPT, Gemini, and Perplexity.
A 3-person growth team can complete the audit and canonical page in a week, then batch profile updates over 2-3 weeks. The tradeoff: escalations are slower (7-30 days) but necessary for platform-owned blurbs; meanwhile, invest in sources you control to influence retrieval faster.
Correction Loop: Steps, Goals, Evidence, Timelines, Owners
Add Organization and Product schema to your canonical page with precise fields: legal name, founders, launch date, headquarters, SameAs links to LinkedIn, Crunchbase, Github, app stores, and recent press. Use Article schema on misconception posts, and keep last-modified current to hint freshness.
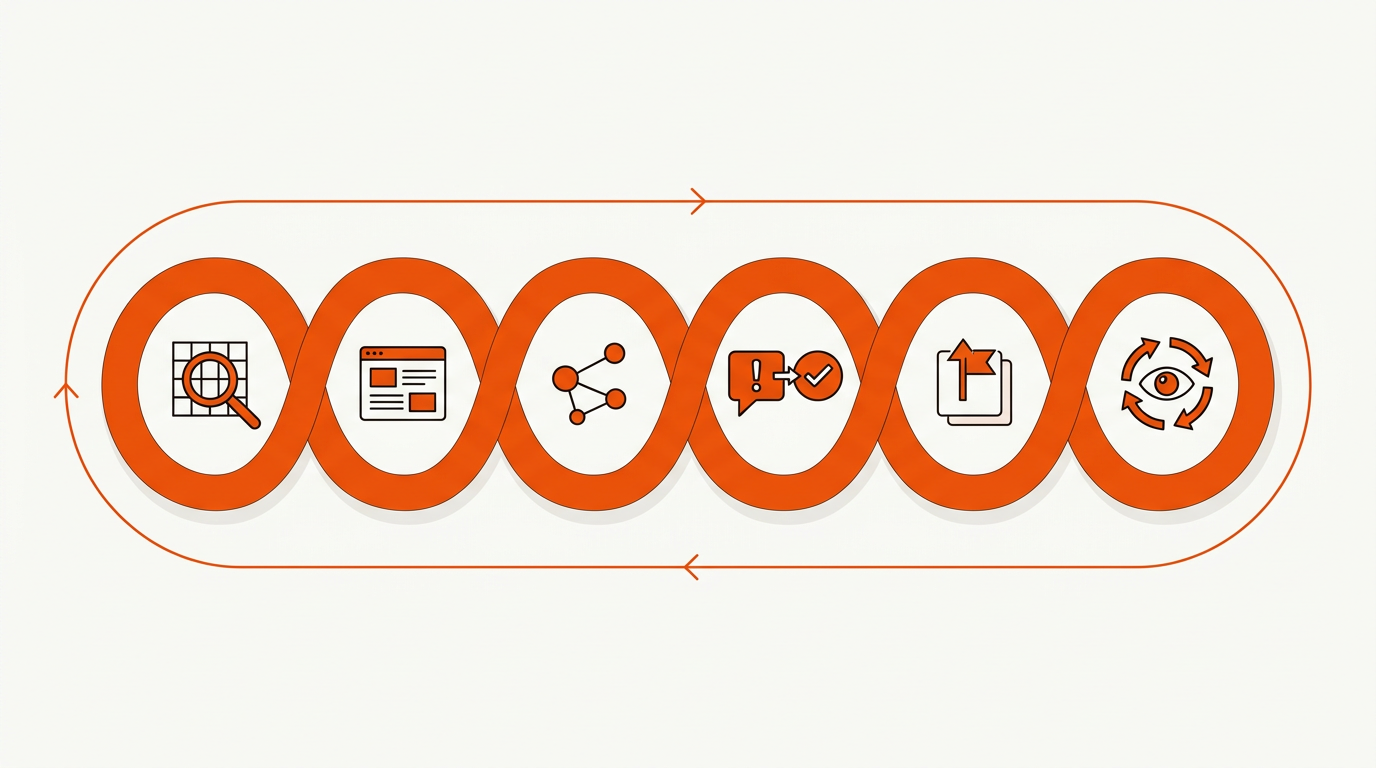
You can build this loop manually in weeks, or automate it now. Mergeflo is an autonomous SEO platform for startups, providing continuous SEO execution without the need for in-house teams or agencies. Map the entity audit, generate a canonical facts page, and queue misconception posts as structured briefs in one workflow. Mergeflo tracks AI answer changes across models, flags drift, and schedules refreshes automatically. A 3-person growth team can run weekly fixed-prompt rechecks while Mergeflo suggests the exact paragraph or schema block to publish; for deeper context, see our guide on how to rank in ChatGPT.

Address operational questions that block durable fixes and AI citation.
Most changes register within 1-3 weeks once your canonical facts page is live and corroborated by third-party profiles. Speed depends on crawl frequency and the authority of your sources. Use a weekly prompt set to verify progress and keep publishing reinforcement where retrieval is still weak. We see ChatGPT wrong brand information drop sharply after 2-3 corroborating citations index.
No. High-trust citations help, but a well-structured facts page plus consistent SameAs links to LinkedIn, Crunchbase, Github, app stores, and press often outperforms a thin or outdated wiki. Focus on clarity, recency, and corroboration that machines can parse. We have corrected summaries for seed-stage startups without Wikipedia within 14 days.
Yes. Start with Organization and Product schema that includes legal name, founders, launch date, and SameAs links to key profiles. Add Article schema for misconception posts and ensure your canonical facts page uses WebPage with breadcrumb and last-modified fields. Validate with Google Rich Results Test and keep JSON-LD under 10KB for reliability.
Prompting can reduce in-session mistakes by constraining sources and asking for citations, but it won’t persist across users. Durable fixes require public, indexable evidence. Use prompts to test whether your new sources are discoverable and being retrieved consistently. Keep a fixed prompt set to confirm that chatgpt wrong brand information no longer appears across models.
