
AI-citable pages get quoted in AI answers without classic rankings. Build pages that state a clear claim in the first 100 words, carry machine-readable facts, show evidence, and expose tidy anchors for attribution. This checklist gives you the construction spec for AEO/GEO so your pages are easy to retrieve, ground, and cite.
A page designed for citations forces clarity. Put a decision table or quantified claim near the top, back it with first-party data, and mark it up. Assistants resolve anchors. Give them IDs, schema, and primary sources.
If you run a 2-5 person growth team, this is speed with control. You can ship AI-citable pages this week and watch assistants pull from your sections.
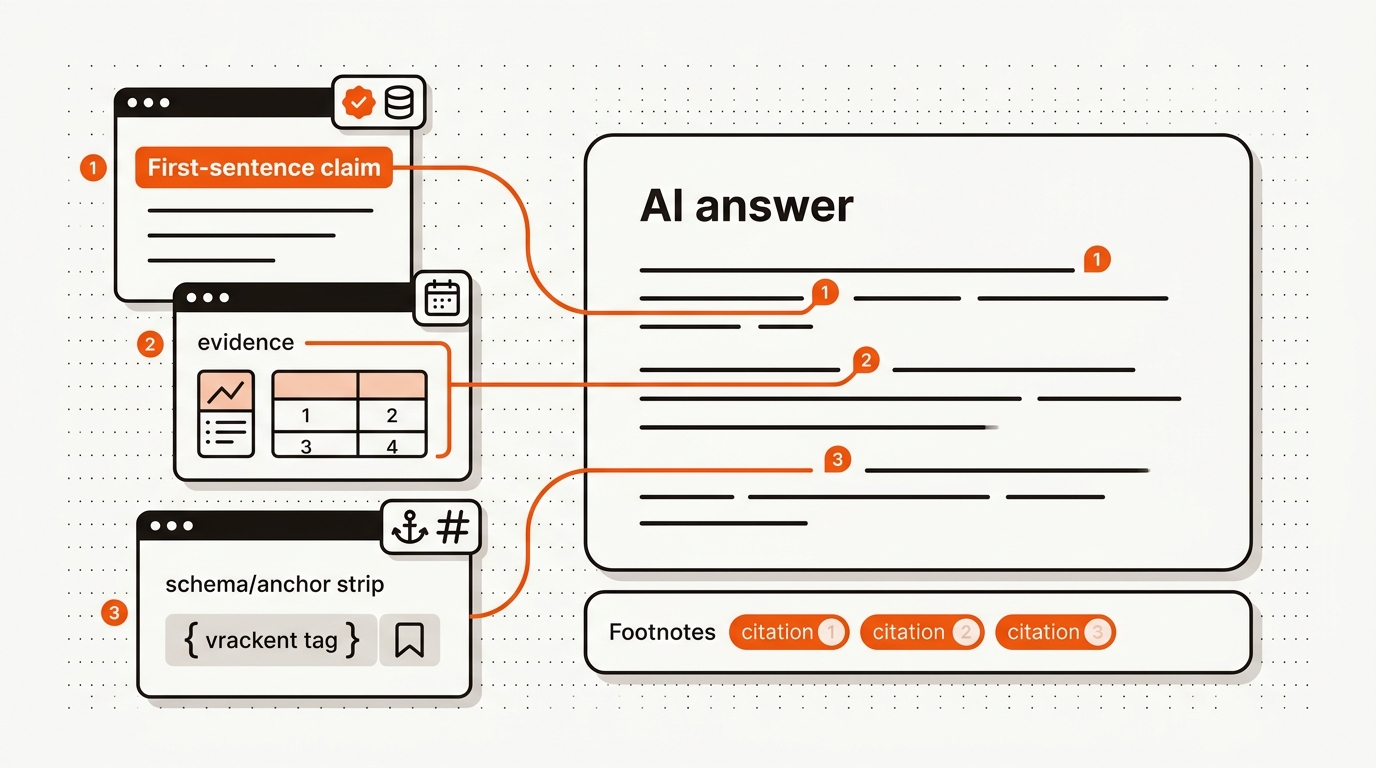
AI assistants quote what they can ground. A founder writing a 1,500-word essay without explicit claims, evidence, anchors, or schema gets skipped, even at top-3 rankings. For startups at 1,180 monthly impressions, citeability is leverage: one AI-citable page can generate more visits than five generic posts. The construction spec, claim first, evidence early, schema clean, costs no extra time once you build the pattern into your template.
Most tools track if you were cited; few tell you how to be citeable. Dashboards miss the construction moves that AI systems use to ground an answer: direct claims, evidence blocks, schema types, and stable anchors.
Use tracking to confirm wins, then copy the elements that got quoted. For context on surfacing across assistants, see the broader guide on AI search visibility and the construction stack inside our generative engine optimization platform. Cross-check guidance with Google Search Central on structured data and Perplexity’s discussion of citations.
Most misses are mechanical. Slow pages, floating headings without IDs, and no per-claim sources reduce selection odds. Fix construction and your DR ceiling rises.
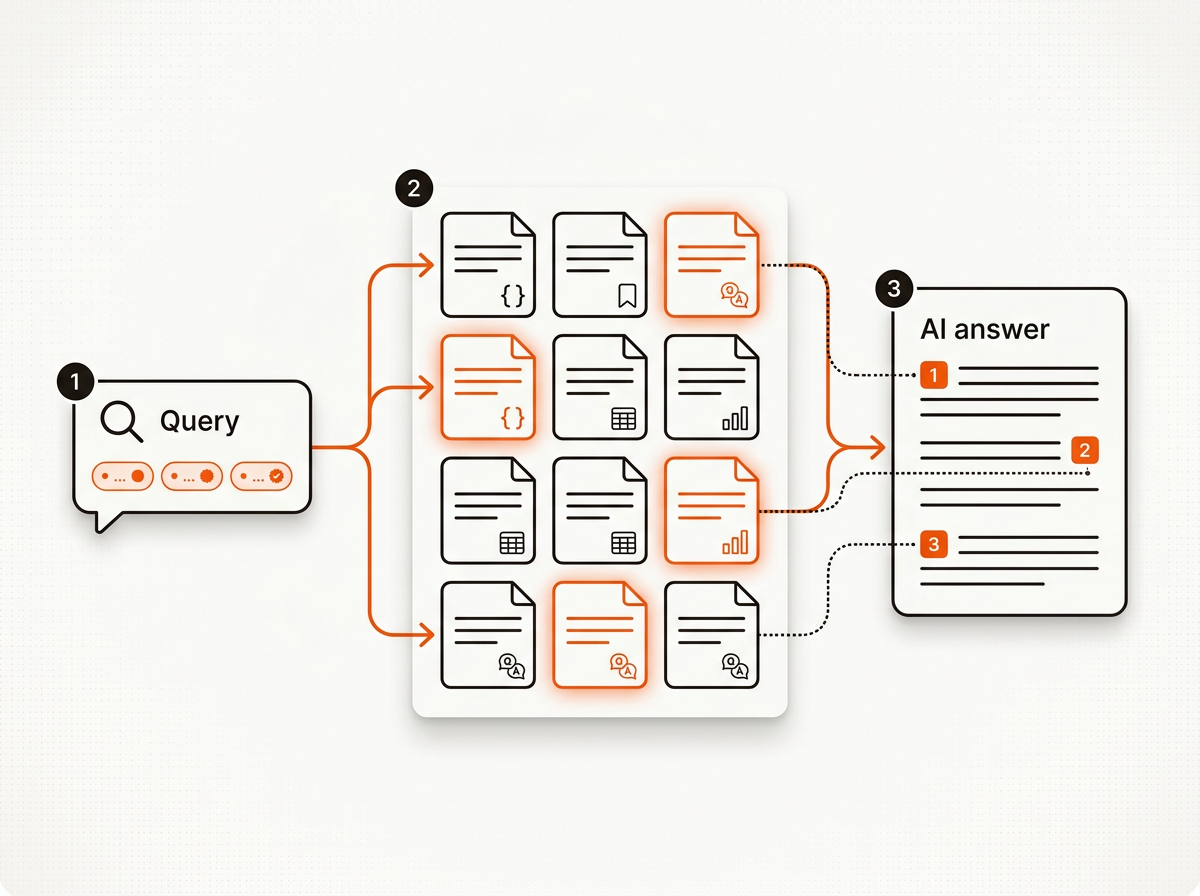
Design for grounding, not just skimming: claim early, prove fast, and mark it up. Use this spec to make your content quotable by assistants and Overviews.
• Above the fold: 1-sentence claim + 2-3 bullet facts with numbers and sources.
• Headings in question form for key intents. Each answers itself in 2-4 lines.
• Evidence blocks: first-party data, steps, definitions, comparisons.
• Anchors: stable H2/H3 IDs; linkable footnotes; updated-on date near the top.
• Schema: Article + FAQPage when usable; HowTo/Product/Comparison where relevant.
• References: outbound links to primary data; author credentials visible.
• Technical: crawlable, canonical clean, fast, mobile-accessible.
Citeability improves when you stack first-party artifacts: benchmarks, study tables, runbooks, and calculator outputs. Link related assets like your take on how to rank in ChatGPT to cluster topical authority.
CITE is a 4-part model to produce AI-citable pages at scale: Claim, I.D. the evidence, Tag, Expose. Start with one explicit claim per section. Identify supporting evidence with numbers and the source. Tag the section with schema and a stable anchor ID. Expose outbound references and author credentials. Tradeoffs: over-tagging without substance reads thin; claims without numbers get skipped. Failure modes: outdated stats, orphaned sections, and hidden authorship.
A 40-page library refactored to this spec: claims in first 100 words, 2 evidence blocks per page, FAQPage schema added, and per-page 3 outbound sources. Over 60 days, Perplexity citations rose from 18 to 51 (+33), ChatGPT browsing links from 6 to 19 (+13), and AI Overviews inclusions from 4 to 9 (+5). Average time-on-page stayed flat at 2:07, but assistant CTR to site grew from 0.6% to 1.9% on tracked queries (n=320).
That is 33 + 13 + 5 = 51 net new citations/inclusions across engines. If each cited answer drives 12 visits on average, that is 51 x 12 = 612 assistant-driven visits in the period. With a 1.9% CTR, 320 tracked queries x 1.9% ≈ 6 clicks per 100 queries, or ~6.1 per 320-query slice.
Pick a path that can produce consistent, schema-valid, evidence-backed pages.
Manual builds fit when you need 5-10 proofs-of-concept. Expect 3-5 weeks to ship the first 10 pages with mixed anchor quality and ad hoc evidence work. Cash cost is low ($0-2k), but it breaks beyond 20 pages as indexing lag compounds and QA drifts.
Agencies deliver polish but slow cycles. Scoping proper schema and anchors adds 1-2 weeks on top of content creation, pushing the first 10 pages to 4-8 weeks. Budgets land between $6k-20k per month. Evidence is often secondary sources unless you supply data.
AI tools publish fast but need ops to avoid thin claims. You can ship 10 pages in 1-2 weeks, but out of the box you get basic schema and weak sourcing. Without prompts tied to your data warehouse or first-party studies, assistants skip you.
Dashboards do not produce pages. They confirm wins and expose misses. Use them to watch citations and surface which sections get quoted. Pair them with build capacity.
Mergeflo combines speed with per-page validation. Expect 1-2 weeks to the first 10 AI-citable pages, with validated anchors and schema, and prompts wired for first-party citations. For lean teams, this keeps throughput high without trading off evidence. Reference tracking once live with AI content visibility tracking to spot what elements get cited and standardize them.
Ship pages that AI systems can ground without guessing.
1. Direct answer in first 100 words with a number.
2. Updated-on date and expert byline above the fold.
3. H2/H3 in question form for top intents.
4. Two evidence blocks per key section with outbound primary sources.
5. Stable anchor IDs for every H2/H3.
6. Article + FAQPage schema; add HowTo/Product/Comparison when relevant.
7. One table that crystallizes a decision or dataset.
8. First-party artifact per page: benchmark, calculator, or mini study.
9. Clean canonical and sitemap entries; indexable and fast.
10. Alt text on images; accessible headings.
11. Clear disclaimers in YMYL niches; author credentials visible.
12. Internal links to the topical cluster to reinforce entity alignment.
Use this to audit and rebuild. When you approach 50+ pages, workflows matter more than tips; see the platform comparison for AEO/GEO execution in our answer engine optimization platform overview.
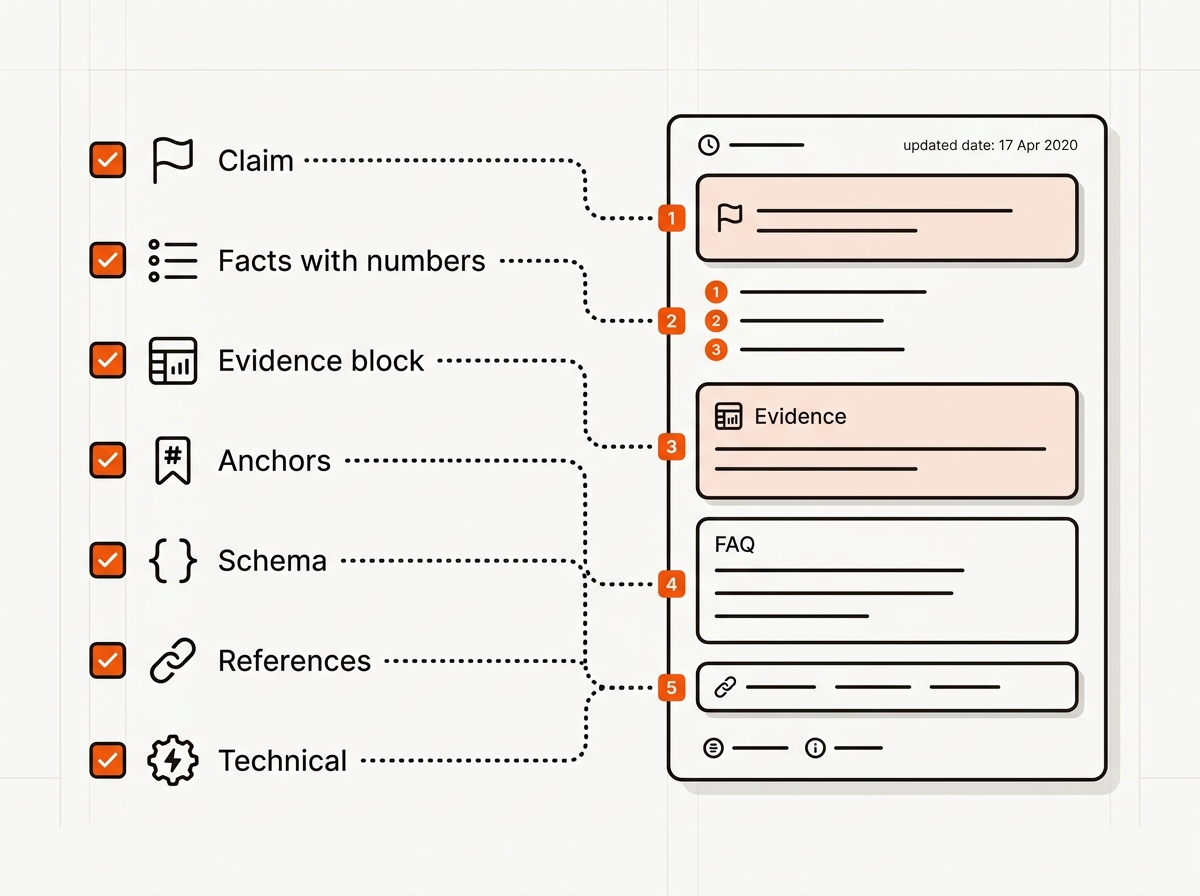
Keep answers short, source-backed, and anchored so assistants can lift them.
Track citations weekly in assistants and Overviews, and attribute quotes to on-page elements. Use GSC to watch Discoverability and impressions on long-tail question queries. Set a weekly review on the same 10 prompts and log every citation by section so you can correlate which on-page elements actually got quoted by each assistant.
Yes, but you can win citations before heavy link building. Aim for 2-3 editorial mentions per cornerstone and ensure each page links to primary sources. Pages can earn citations at DR 10-20 if evidence is dense and entities are explicit, but plan 2-3 editorial mentions per cornerstone to graduate from one-off citations to consistent inclusion.
Start with Article and FAQPage. Add HowTo for procedural content, Product for specs, and mark comparison tables. Validate in Rich Results Test and keep JSON-LD tidy. Start with Article and FAQPage; add HowTo for procedural content and Product for specs; validate every change in Rich Results Test before push to production.
Two quant points per section are a strong baseline: one benchmark and one operational metric with timeframe and sample size. Two quantified data points per section with a timeframe and sample size beats one large dataset buried below the fold, assistants extract what they can ground quickly.
Above the fold or immediately after the first claim. Assistants often lift the first tight table they encounter. Above the fold or directly after the first claim, assistants often lift the first tight table they encounter, so a 5-row decision matrix in the intro pays back the formatting time.
Ensure each H2/H3 has a stable ID and uses readable, intent-aligned text. Avoid dynamic IDs that change on deploy. Use readable kebab-case IDs that match the H2 text; avoid dynamic IDs that change on deploy because every break invalidates the prior month of citations.
Fragmented schema, no update cadence, and thin evidence. The system fails beyond 200 pages if indexing lags and anchors drift. Fragmented schema, missing update cadence, and thin evidence break the system past 200 pages, bake the construction spec into a CMS template before the page count crosses 50.
Yes. Stats, definitions, and comparisons make clean citation targets. Link them into how-tos for entity reinforcement. Yes, stats pages serve as citation magnets while how-to pages serve as conversion paths; keeping them separate lets you tune format per intent without dilution.
External sources:
• Google Search Central: Structured Data
• Perplexity Blog: Citations and Sources
• Schema.org: FAQPage
• GEO for Startups: Earn AI Mentions Before You Have DR
• Startup SEO Checklist: Build Clusters That Rank
