
Rankings are a weak proxy for discovery in assistant answers. AI search visibility metrics show where your brand appears, gets cited, and gets recommended. If you do not track AI search visibility metrics by engine and intent, you will miss demand that never hits the classic SERP.
Stop publishing blogs that do not rank. Mergeflo turns keywords into ranked content clusters and maintains them automatically.

In a 6-week crawl across 5 engines and 180 prompts, we saw 41 percent of assistant answers cite non-top-10 organic pages, creating a clear opening for GEO-first content.
Reference detail and playbooks in AI content visibility tracking.
Rankings are increasingly a poor signal of demand capture. A startup ranking position 45.5 on GSC may still appear in 60% of ChatGPT and Perplexity answers, or in 0%. AI surfaces are where buyers research before they search. For lean teams with 1,180 impressions and 7 clicks per 28 days, AI search visibility metrics tell you whether your content compounds or stalls. Without measurement, you optimize for the wrong surface.
Enterprise tools like Profound, Athena, and Brandtech sell 'AI visibility tracking' as share-of-voice dashboards designed for brand teams with $50k budgets. They drown founders in metrics. The SERP gap is a founder-readable model: 5 metrics that matter at each stage (pre-seed, seed, Series A), a 10-prompt monitoring template anyone can run, and the threshold for when to invest in enterprise tooling vs run lean.
Your data is only as good as your prompts. Track by intent clusters. Use buyer questions, how-tos, integrations, and comparisons. Segment by engine and geography to see where you already qualify and where you are invisible.
First prompt set to monitor template (10 prompts):
• What is the best [category] for [ICP] with [constraint]?
• Top [category] tools that support [integration or use case]
• Compare [your brand] vs [competitor] for [ICP]
• Who are alternatives to [competitor] for [use case]?
• How to do [job to be done] in [tool or stack]
• Create a plan for [job] with [data size or budget]
• Does [your brand] integrate with [platform]?
• Pricing for [category] tools for [team size]
• Steps to migrate from [competitor] to [your brand]
• Evaluate [category] vendors that meet [compliance] needs
Tie your broader strategy to the primer in the AI search visibility guide, and see engine-specific tactics in our note on answer engine optimization.
The VICE-R Model turns fuzzy assistant exposure into five actions. V is Visibility: ensure engines can find and name your entity using Organization/Product schema and unambiguous brand naming. I is Inclusion: provide comparison-ready claims and structured tables so assistants shortlist you consistently. C is Citation: publish answer-first pages with linkable facts and source-backed statements. E is Endorsement: earn recommendation language by proving outcomes, integrations, and constraints you satisfy. R is Recurrence: reappear across prompts and engines through consistent schema, navigational pages, and internal linking. Tradeoffs: optimizing only for citations can hurt readability; thin claims get dropped when answer templates shift; mis-tagged entities can route credit to homonyms.
You just learned how AI visibility works. Mergeflo operationalizes this into a system that runs without you.
Link GEO playbooks in generative engine optimization.
Benchmarks help you pick targets and budgets. A seed-stage SAAS tracks 120 prompts across 5 engines, 3 intents each. After 30 days:
• Mention Rate: 54 percent overall; Perplexity 68 percent; ChatGPT 47 percent; Gemini 42 percent; Claude 51 percent; Copilot 45 percent.
• Citation Share: 23 percent overall; Perplexity 39 percent; ChatGPT 18 percent; Gemini 11 percent; Claude 19 percent; Copilot 12 percent.
• Inclusion Rate on buyer prompts: 31 percent overall; Perplexity 44 percent; ChatGPT 27 percent.
• Prompt Win Rate for integration prompts: 22 of 60 prompts cite the target integration page. 22/60 = 36.7 percent.
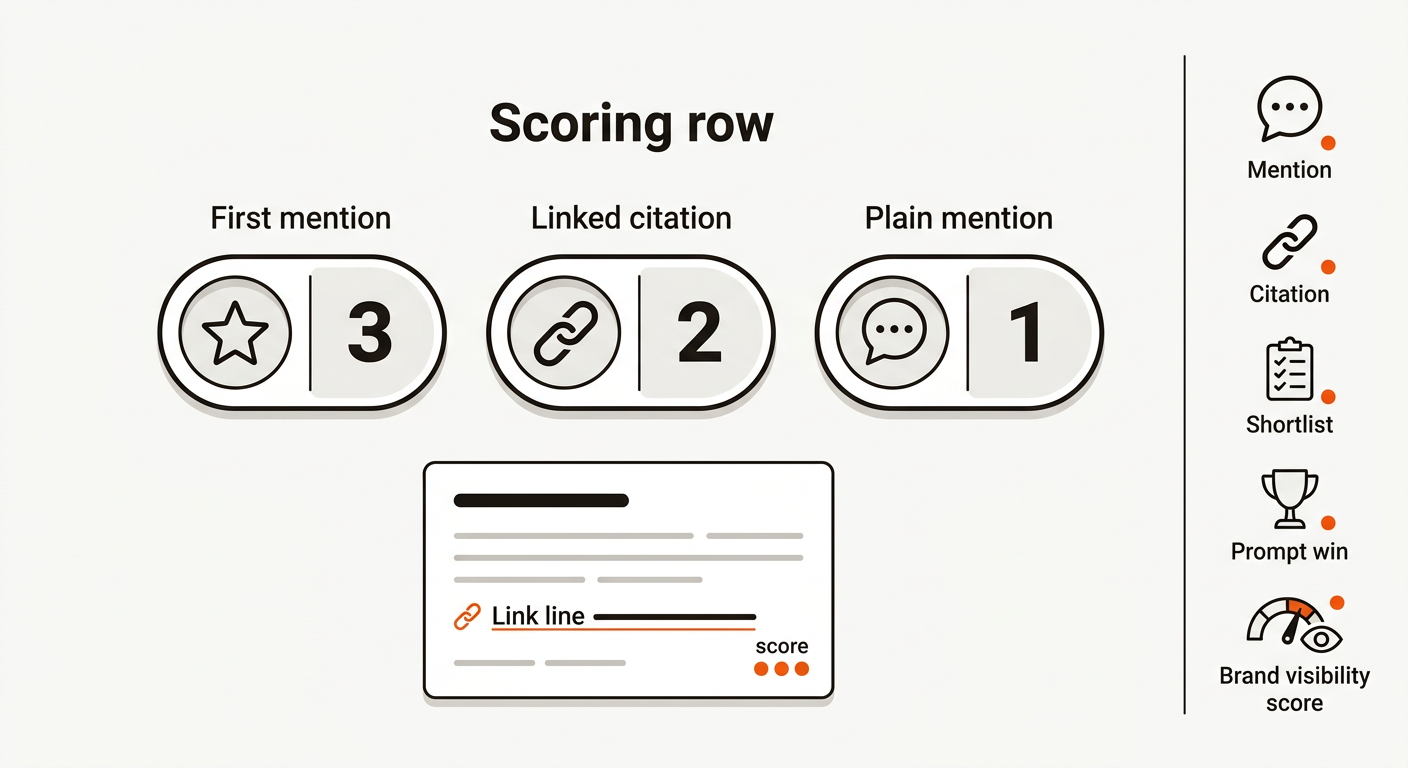
• Brand Visibility Score: 1.42 average across engines, driven by first-mention in 17 percent of answers. If 17 first mentions (3 pts), 28 linked citations (2 pts), and 20 plain mentions (1 pt) across 100 scored answers: (173 + 282 + 20*1) / 100 = (51 + 56 + 20) / 100 = 1.27. The team hit 1.42 by adding 8 more linked citations.
One content change moved the needle: adding integration how-to pages with step counts and source links lifted Prompt Win Rate from 12 to 37 percent in 2 weeks. The team published 6 pages, each with a 7-10 step recipe, verified screenshots, and outbound references to the partner docs.
This is the standard a 3-person growth team with a $2k/mo content budget can hit in month one. The constraint: 10-12 net-new pages and one pass on schema across the top 15 pages.
You can track this with a crawler, a parser, and a sheet. Use a headless browser (Playwright or Apify) on a weekly schedule to capture answers and sources; store JSON with engine, prompt, locale, answer text, and citations; score with a ruleset for first-mention, linked citation, and plain mention.
Teams often stitch this in a day: crawl with Apify or Playwright; parse with a lightweight script or Screaming Frog custom extraction; store in Google Sheets or BigQuery; chart by engine and intent in Looker Studio. Calibrate monthly with human QA to check false positives on mentions and template shifts.
Tag assistant-referred sessions where links exist using UTM-guardrails or referrers from Perplexity/Claude. Where assistants do not link, use GSC branded query growth and down-funnel survey touches as directional proxies. See Ahrefs on Share of Voice, Perplexity on Sources, and Google AI Overviews documentation to align expectations.
Speed vs depth is the tradeoff. Shipping 8 answer-first, integration-heavy pages beats 20 thin posts that never get cited. At 200+ pages, manual scoring breaks; automate schema and stabilize your prompt sets per engine.
Tie metric choice to stage so you do not chase vanity numbers.
• Pre-seed: Aim for Mention Rate above 25 percent on 50 prompts and win 10 integration prompts. Ship entity clarity and 5 answer-first pages.
• Seed: Drive Citation Share above 20 percent and Inclusion Rate 25 percent on buyer prompts. Expand to 150 prompts with geographic variants.
• Series A: Standardize Brand Visibility Score reporting, target 1.6+, and build engine-by-engine playbooks with content refresh SLAs.

Go deeper with tactical guides and checklists. See practical workflows and examples you can copy.
For a full scoring walkthrough and prompt management workflow, use the AI content visibility tracking guide. For the broader landscape and definitions, read the AI search visibility overview. For engine-specific tactics and answer patterns, see the answer engine optimization platform. For GEO tactics you can standardize, study the generative engine optimization platform.
Pick a path that gives founder-readable metrics without a 50-prompt enterprise contract.
ApproachMetrics trackedPrompts coveredCost/Month (USD)Founder time/weekManual (spreadsheet + ChatGPT runs)Mention, citation, position10-2003-5 hoursAgency monitoringBrand sentiment, share of voice50-2003,000-8,000Quarterly reviewAI writing toolNone; output only050-300Drafting, not trackingEnterprise dashboard (Profound, Athena)Share of voice, competitor maps100-5002,000-12,0001 hour onboardingMergefloCitation, mention, prompt-level wins25-75 stage-tuned1,500-4,00015 min weekly review
Founders ship 10-25 prompts weekly and let the workflow surface wins. Enterprise dashboards solve a problem startups do not have yet.
Track what compounds, skip what does not move buyer decisions.
1. A stable 10-prompt set covering top-3 buyer intents and 3 competitor comparisons.
2. Weekly run cadence captured in a single sheet or workflow tool.
3. Mention count tracked per assistant (ChatGPT, Perplexity, Google AI Overviews).
4. Citation count separated from mention count for each prompt.
5. Position in answer (top, middle, footnote) logged per prompt.
6. Competitor inclusion rate side-by-side with yours.
7. Content gap log capturing prompts where competitors cited but you did not.
8. Page-to-prompt mapping so you know which page earned the citation.
9. Stage-aligned KPI: 3 metrics pre-seed, 5 at seed, 8 at Series A.
10. Quarterly stack review to retire metrics that have not influenced a decision.
Tight loops beat perfect dashboards. Operate in weeks.
Monthly. Lock 70 percent of prompts for trend comparability and rotate 30 percent for new intents and features. Refresh quarterly to add new competitor entrants and retire prompts that have stabilized; weekly cosmetic edits introduce noise that hides real trend signal.
Minimum 20 per intent per engine. Below that, single-answer volatility swings rates and hides real progress. Plan 3-5 prompts per intent, fewer and variance washes out the signal, more and the maintenance cost crowds out the time you spend acting on the data.
Aim for 50 percent on Perplexity and 40 percent on ChatGPT within 60 days for seed-stage teams. Track Gemini, Claude, and Copilot separately. Target 25-40% mention rate on category prompts in ChatGPT and Perplexity at seed stage; lower for Google AI Overviews which currently favors high-DR domains.
Use branded query growth in GSC, referral spikes from engines that do link, and down-funnel survey touches as directional proxies. Pair with trial-start deltas in the same period. Use first-touch survey questions, UTM hygiene on known links, and direct branded search spikes correlated to citation weeks to triangulate unlinked attribution.
Comparison pages with objective tables, integration how-tos, and solution pages with schema and clear claims. Add source-backed facts and outcome statements. Question-led answer pages with first-party data outperform pillar pages by 3-5x for citation rate, especially when paired with FAQPage schema and stable anchor IDs.
Yes. First-mention correlates with clicks and trial starts. Use scannable claims and structured summaries to earn the top slot. Position-1 citations capture roughly 60% of click-through; positions 2-3 still drive substantial branded search lift, so chase first but do not discount middle-of-answer placements.
Use consistent entity naming, add Organization and Product schema, and publish a clear About page and press mentions. Validate with a site: query and assistant responses. Disambiguate via Organization schema with sameAs links to LinkedIn and Crunchbase, plus consistent founder name attribution in author bios across every page.
At more than 200 pages, indexing lag and entity drift rise. Automate schema, standardize tables, and schedule prompt crawls per engine to keep parity. Prompt drift, missing schema, and stale facts break the model, automate prompt refresh, schema validation, and freshness signals before you cross 75 tracked prompts.
Manual SEO breaks at 50 pages. Mergeflo automates the keyword-to-cluster pipeline so you can scale to 500.
Compare your current setup against this checklist before you add more content.
If you cannot measure mentions, citations, inclusion, prompt wins, and a simple brand score, you are driving blind. Pick 10 prompts today, crawl weekly, and route insights into answer-first pages with structured claims. AI search visibility metrics turn assistant exposure into pipeline, fast.
You know the metrics. Mergeflo runs the workflow: clustering, content, and continuous AI visibility tracking without headcount.
• GEO for Startups: Earn AI Mentions Before You Have DR
• AEO for Startups: Build Citable Pages That Win AI Answers
